Pythonʹ��Selenium�Զ����аٶ�������ʵ��
| ����ʱ�䣺 | 2023/3/10 16:48:38 | ������ | 2003 |
���ǽ������һ���dz��ʺ����ֵ�python�Զ���С��Ŀ����Ŀ��С�����������ȫ������һ���Զ���������ҳ�������СӦ�ã��������������ٶ���ҳ�������ؼ��ʣ���������������浽һ���ļ��������ӷdz��ʺ�����ѧϰPython�����Զ����������ܹ��˽����ʹ��Selenium�����һ���֪��һЩ�������õ�С���ߡ�
��Ȼ���˰Ѳ�����ҳ��Ȼ�����ҳ�Ĺؼ����ݱ���������Ӧ��һ�ɳ����������棬�ðɣ����������ô��ȡ���ݣ����㡣���ǣ��Ҹ�Ը�����Ϊ��������ˡ�
�ҽ�����ܵ���Ŀʹ��Selenium��Selenium ��֧�� web ������Զ�����һϵ�й��ߺͿ���ۺ���Ŀ��Selenium �ĺ����� WebDriver������һ����дָ��Ľӿڣ�����������������л������С�
��������Ӳ�����š�
��װ Selenium
����ʹ�� pip ��װ Python �� Selenium �⣺pip install selenium
����ѡ�Ҫִ����Ŀ���������������Ҫ��װ�ض���������� WebDriver �������ļ���
���� WebDriver �������ļ� ������ ϵͳ PATH �������� ��.��
���ڱ���������汾����������İ汾��һ�����⣬��ϵͳPATH�������������ñȽϷ�����������ʹ��webdriver_manager��
��װ Install manager:
pip install webdriver-manager
���
����ģ�飺
from selenium import webdriverfrom webdriver_manager.chrome import ChromeDriverManagerfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.common.keys import Keys
�������Ƕ���һ����Search_Baidu�� ����Ҫ���ڳ�ʼ���������Զ�������ķ����������ر��������
class Search_Baidu:def __init__(self):def search(self, keyword):def tear_down(self):
���������Ƿֱ����ÿ��������ʵ�ֹ��̡�
def __init__(self): #��캯�������ڳ�ʼ��selenium��webdriver url = ��https://www.baidu.com/�� #���ﶨ����ʵ������ַ self.url = url options = webdriver.ChromeOptions() options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2}) # ������ͼƬ,�ӿ�����ٶ� options.add_experimental_option(��excludeSwitches��, [��enable-automation��]) # �˲������Ҫ������Ϊ������ģʽ����ֹ��������վʶ�����ʹ����Selenium# ����ʹ��chrome�����������ʹ�����ǸղŰ�װ��webdriver_manager��chrome driver������ֵ��������������options���� self.browser = webdriver.Chrome(ChromeDriverManager().install(), options=options) self.wait = WebDriverWait(self.browser, 10) #��ʱʱ��Ϊ10s�������Զ�����Ҫ�ȴ���ҳ�ؼ��ļ��أ�������������һ��Ĭ�ϵĵȴ���ʱ��ʱ��Ϊ10�� def tear_down(self): self.browser.close() #��ر������
����������ͷϷ��д���Dz���������IJ��裬�������������ٶ���ҳ�����������ؼ��֣�Selenium���ȴ�����������������������Ŀ����ַ���浽�ļ��
def search(self, keyword): # �ٶ���ҳ self.browser.get(self.url) # �ȴ���������֣����ȴ�10�룬����ʱ���� search_input = self.wait.until(EC.presence_of_element_located((By.XPATH, ��//*[@id="kw"]��))) # �����������������Ĺؼ��� search_input.send_keys(keyword) # �س� search_input.send_keys(Keys.ENTER) # �ȴ�10���� self.browser.implicitly_wait(10) # �ҵ����е�������� results = self.browser.find_elements_by_css_selector(".t a , em , .c-title-text") # �������е�������� with open("search_result.txt","w") as file: for result in results: if result.get_attribute("href"): print(result.get_attribute("text").strip()) # ��������ı��� title = result.get_attribute("text").strip() # �����������ַ link = result.get_attribute("href") # д���ļ� file.write(f"Title: {title}, link is: {link} n")
��λ��ҳԪ��
����ͷ�и��ؼ��㣬������ε�λ��ҳԪ�أ�
���磺
search_input = self.wait.until(EC.presence_of_element_located((By.XPATH, ��//*[@id="kw"]��)))
����
self.browser.find_elements_by_css_selector(".t a , em , .c-title-text")
����ȷ������Աͨ����ַ�ҵ���ң������Ϳ�ݣ������XPATH��CSS Selector������ҳԪ�صĵ�ַ����ô��εõ��أ�
��һ������Chrome�Դ��Ŀ����߹��ߣ����Կ�ݼ�F12��Ҳ�����Լ�����ͼ���ҵ���
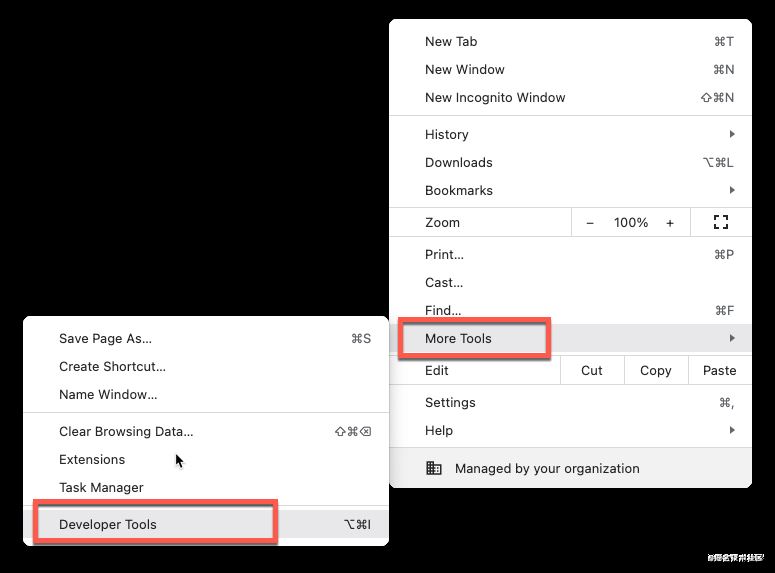
Ȼ���ڰٶ��������Ҽ���
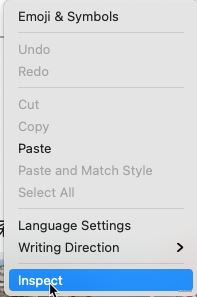
�ҵ�������HTMLԪ�أ�

��HTMLԪ���Ҽ�������XPath��ַ��
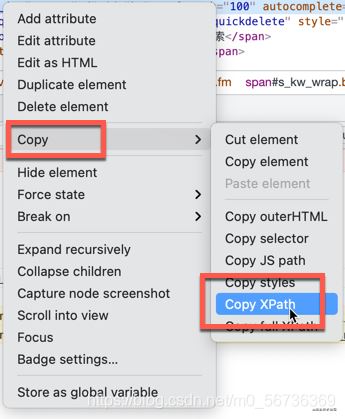
���DZȽϼĶ�λ��ҳԪ�صķ��������������Ƕ�λ�������Ԫ�ص�ʱ���������鷳������ͼ��
���Dz��ܵ����Ķ�λÿ��Ԫ�أ�����Ҫ�ҵ����ɣ�һ�ΰ����е���������ҵ���Ȼ��һ��list�����Ǻñ������list�������ôʵ���أ�
���������������һ��������SelectorGadget
SelectorGadget��һ��CSS Selector����������ҿ��������Ĺٷ��ĵ��ҵ������ʹ��˵�������������һ�£�
��������SelectorGadget�����һ��ͼ��
��������������Ŀ��

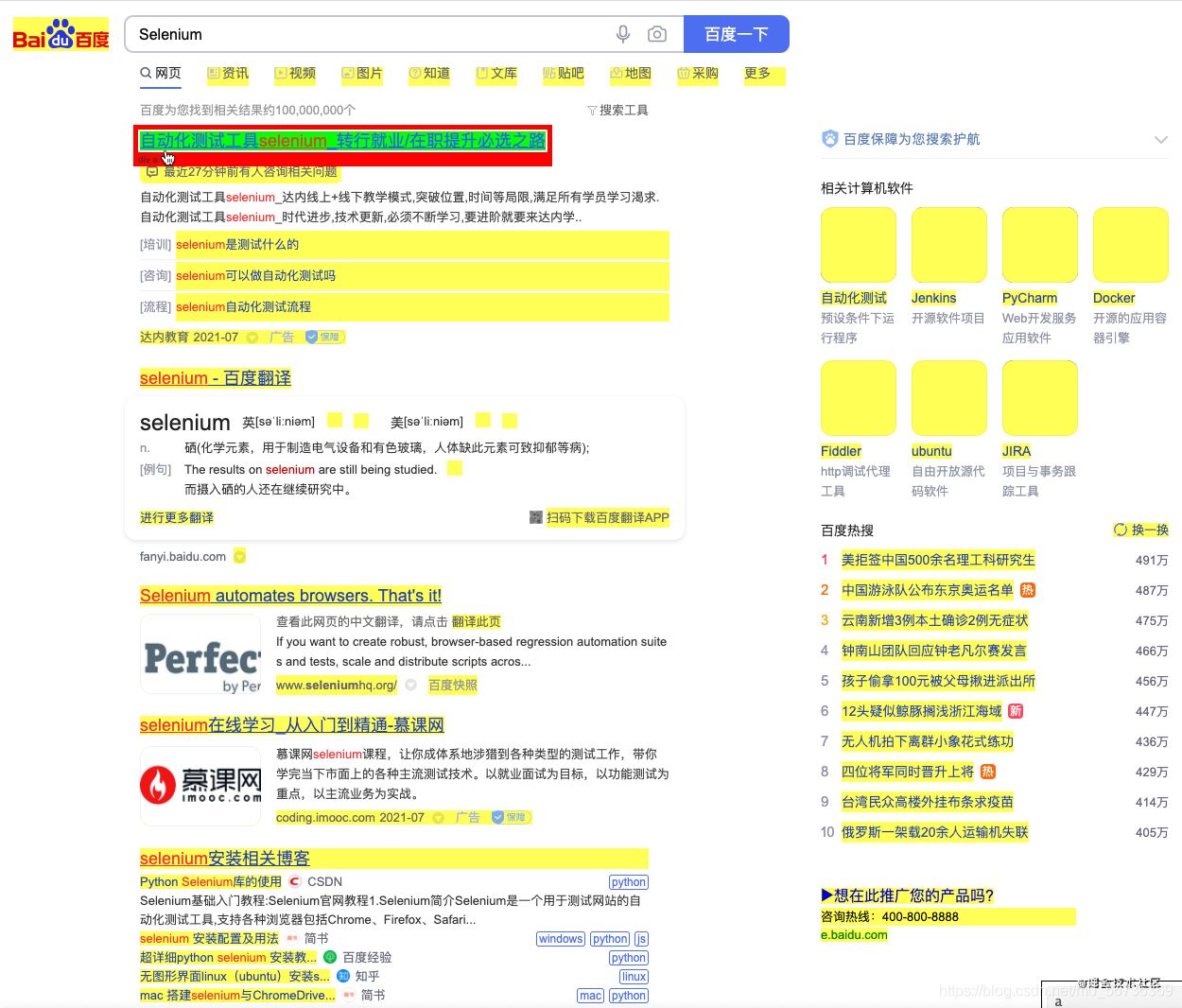
Ȼ����������ҳ�����������������Ҫ��λ��Ԫ��

Ȼ��ҳ�������������ӣ�
���л�ɫ�IJ���˵������ѡ���ˣ�������Dz���Ҫ��Ԫ�أ��Ҽ������ʹ����Ϊ��ɫ��˵������ȥ���ˡ����û�б�ѡ����������Ҫ��Ԫ�أ��������ѡ������ʹ����Ϊ��ɫ���������ϣ��ѡ���ҳ��Ԫ�ض��������ɫ����ɫ������ͼ��
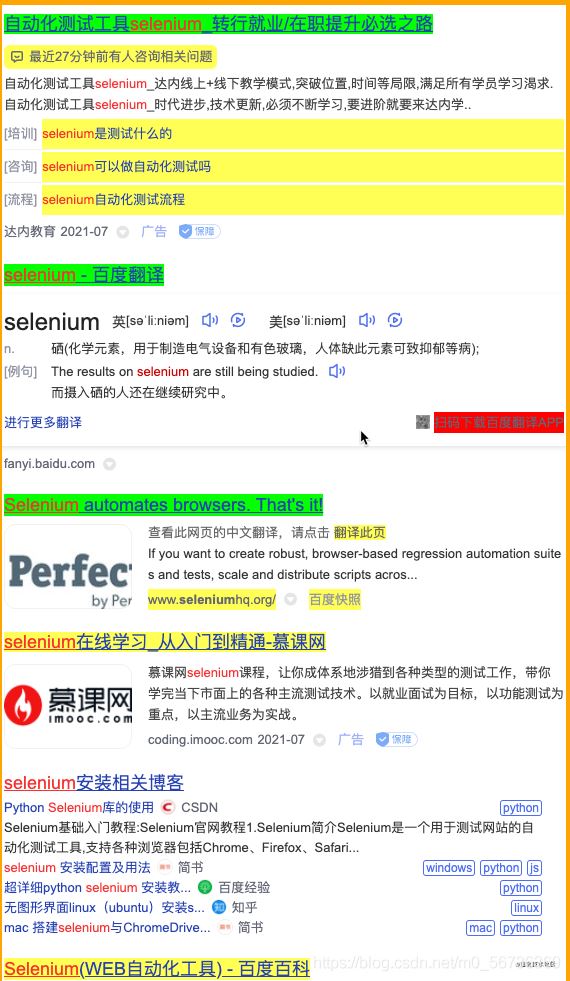
���ǾͿ��Կ���������������ΪCSS Selector�ˡ�

ͨ��CSS Selector�ҵ����е����������
results = self.browser.find_elements_by_css_selector(".t a , em , .c-title-text")
���ˣ����Ǿ�ʵ������ô����СӦ���ˣ���ʵselenium���ǰ��������Զ�������ҳԪ�أ��������Ƕ�λ��ҳԪ�ؾ�������֮�أ�ϣ�����ĸ������һ�������
�����Ҹ��ϴ��룺
from datetime import timefrom selenium import webdriverfrom webdriver_manager.chrome import ChromeDriverManagerfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.common.keys import Keysclass Search_Baidu: def __init__(self): url = ��https://www.baidu.com/�� self.url = url options = webdriver.ChromeOptions() options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2}) # ������ͼƬ,�ӿ�����ٶ� options.add_experimental_option(��excludeSwitches��, [��enable-automation��]) # �˲������Ҫ������Ϊ������ģʽ����ֹ��������վʶ�����ʹ����Selenium self.browser = webdriver.Chrome(ChromeDriverManager().install(), options=options) self.wait = WebDriverWait(self.browser, 10) #��ʱʱ��Ϊ10s def search(self, keyword): # �ٶ���ҳ self.browser.get(self.url) # �ȴ���������֣����ȴ�10�룬����ʱ���� search_input = self.wait.until(EC.presence_of_element_located((By.XPATH, ��//*[@id="kw"]��))) # �����������������Ĺؼ��� search_input.send_keys(keyword) # �س� search_input.send_keys(Keys.ENTER) # �ȴ�10���� self.browser.implicitly_wait(10) # �ҵ����е�������� results = self.browser.find_elements_by_css_selector(".t a , em , .c-title-text") # �������е�������� with open("search_result.txt","w") as file: for result in results: if result.get_attribute("href"): print(result.get_attribute("text").strip()) # ��������ı��� title = result.get_attribute("text").strip() # �����������ַ link = result.get_attribute("href") # д���ļ� file.write(f"Title: {title}, link is: {link} n") def tear_down(self): self.browser.close()if __name__ == "__main__": search = Search_Baidu() search.search("selenium") search.tear_down()
| ��û�жԴ����ۣ� |
|

|

|

|

|

|

|

|

|

|

- ���Ƽ��Ķ�
- �� �ϴ�ɽ��ƺ����ʯ���������ס1...
- �� ������ƺɽ������μ�����ʲôʱ...
- �� �������Ǹ�����ũ����ɱ��������...
- �� ����������ƺɽũ�����˾�99Ԫ...
- �� ��������Ӫ��ѧ ��ҫ2024��...
- �� �������ϴ������������Ŀ����ת...
- �� ��������ƺɽ¶Ӫ����������ɡ��...
- �� ����Ҳ��˽�Ҳ��������ߣ�һ��...
- �� ��֪��ס�������ǰ�������ɽׯ��...
- �� �ش�ͻ�ƣ�������Ժ�ũ�������...
- ���Ƽ�ũҵ����

- ��������Ϫ�ط���ħ��
- ��������Ϫ�ط���ħ����ֲ���أ�רҵ��ֲ��ħ��,��ħ��,�ӽ�ħ[��Ϫ��]
�绰: 










- �������������������
- ������ȣ�����ʡ�˲����������ز������ҵ�����־��Ʒ���ڸ���[������]
�绰:

- �����������ͣ��߲ˣ�
- �����ں���ũҵ��չ����˾רӪ:�����߲����͡���̬�߲�����[������]
�绰:

- �������ϴ����������
- �������ϴ��������������Ԫ�ۺ�����Ŀ��ʹ��Ȩת�ú�����Ŀ��Դ[�ϴ���]
�绰:

- ����С���̻����ܣ���
- ���������Դ��̬���ο�������˾����Ҫ���»��ܣ���ľ������[������]
�绰:

- ����Ұ������Գ��ˣ�
- ����Ұ������Գ��ˣ�����Ұ�������������ϲ�����������Ѷ���[�山��]
�绰:

- �����ʻ�ţ��������ë
- ��ţ�Ǵ�������������Ҫ�����ѿ�����ϵ����������������ʵ�ë[������]
�绰:

- ���컨����ֲ������С
- ���ǵIJ�Ʒ��Ҫ�У� �ݻ�ϵ�У���յ�ա����پա�����ա����[������]
�绰:

- ������ľ����ֲ����
- ������һ�Ҵ���*�������̻� ����ֲ���̻���ľ[������]
�绰:

- ���ݱϽ���Ķӣ������
- ���ݱϽ���Ķӣ�ҿ����������Ҫ�����ѿ�������ժ��Ҳ����ֱ[������]
�绰:
